The next nine-figure GDPR fine will not be a hack. It will be a paste.
Specifically, it will be a marketing manager pasting a customer database into ChatGPT for segmentation, in a company with a written AI policy and zero telemetry.
The policy will be in a shared drive. It will have a neat title page. Someone will have presented it to the board. Compliance theatre remains a thriving sector.
That prediction is less dramatic than it sounds. On 20 December 2024, the Italian Garante fined OpenAI €15 million over ChatGPT-related processing failures. Different facts. Same signal.
LLM data flows are now firmly inside major enforcement. If you still treat prompt leakage as a quirky acceptable-use issue, you are reading the room from 2023.
The enforcement pattern matters. Early GDPR fines often centred on security failures under Article 32. The middle wave went hard at lawfulness under Article 6 and transparency under Articles 12-14.
The next wave is accountability. GDPR Article 5(2) is short and brutal: the controller is responsible for, and must be able to demonstrate compliance with, Article 5(1). “We had a policy” satisfies nobody if you cannot show what happened in the browser, who was warned, what was blocked, and what data left anyway.
Why the next case is about accountability, not just security
Most employee ChatGPT incidents do not start with malice. They start with work.
A marketer wants churn segments by 4 p.m. A support lead wants complaint themes before the QBR. A healthcare SaaS team wants faster triage. So they paste.
Take this customer database export and segment by likelihood-to-churn — give me a marketing strategy for the top quartile. [paste of 18,000 customer records]Cluster these patient feedback responses by complaint type and identify the 50 most at-risk relationships.Anonymise these support transcripts then summarise common complaints.The third prompt is the regulator's favourite trap. If the personal data was pasted before it was anonymised, then the relevant processing already happened. You do not get points for outsourcing the risky step to the same tool that received the raw data.
Article 32 requires appropriate technical and organisational measures, including a process for regularly testing, assessing, and evaluating the effectiveness of those measures. That phrase matters.
Ongoing testing. Assessment. Evaluation. Not a PDF, a training deck, and crossed fingers.
This is where the Friday farce begins. Vendors still sell AI policy generators as if the main threat is blank-page syndrome. Some executives still confuse policy publication with compliance, which is a bit like confusing a fire evacuation poster with sprinklers. Some consultants still advise “ban it and move on,” because nothing says modern governance like pretending your staff stopped using ChatGPT, Copilot, Gemini, or Claude the moment Legal frowned.
They did not stop. They switched devices, personal accounts, and browser tabs.
The three things a regulator will ask, in order
A regulator investigating a GDPR fine employee ChatGPT data paste incident will ask three things.
- Show me the policy.
- Show me the controls.
- Show me the log.
The fine is at step 3.
Step 1 is easy. Everyone has a policy now. Some have three. One for the board, one for staff, and one for the consultant who billed by the page.
Step 2 is where Article 32 starts doing actual work. What technical and organisational measures did you deploy? Did you block obvious PII and financial data from being pasted into public LLMs? Did you warn users in context, not six months earlier in LMS purgatory? Did you limit categories of data? Did you test whether those controls worked in Chrome, where people use the tools?
Step 3 is where Article 5(2) becomes expensive. Can you demonstrate compliance? Not describe it. Demonstrate it.
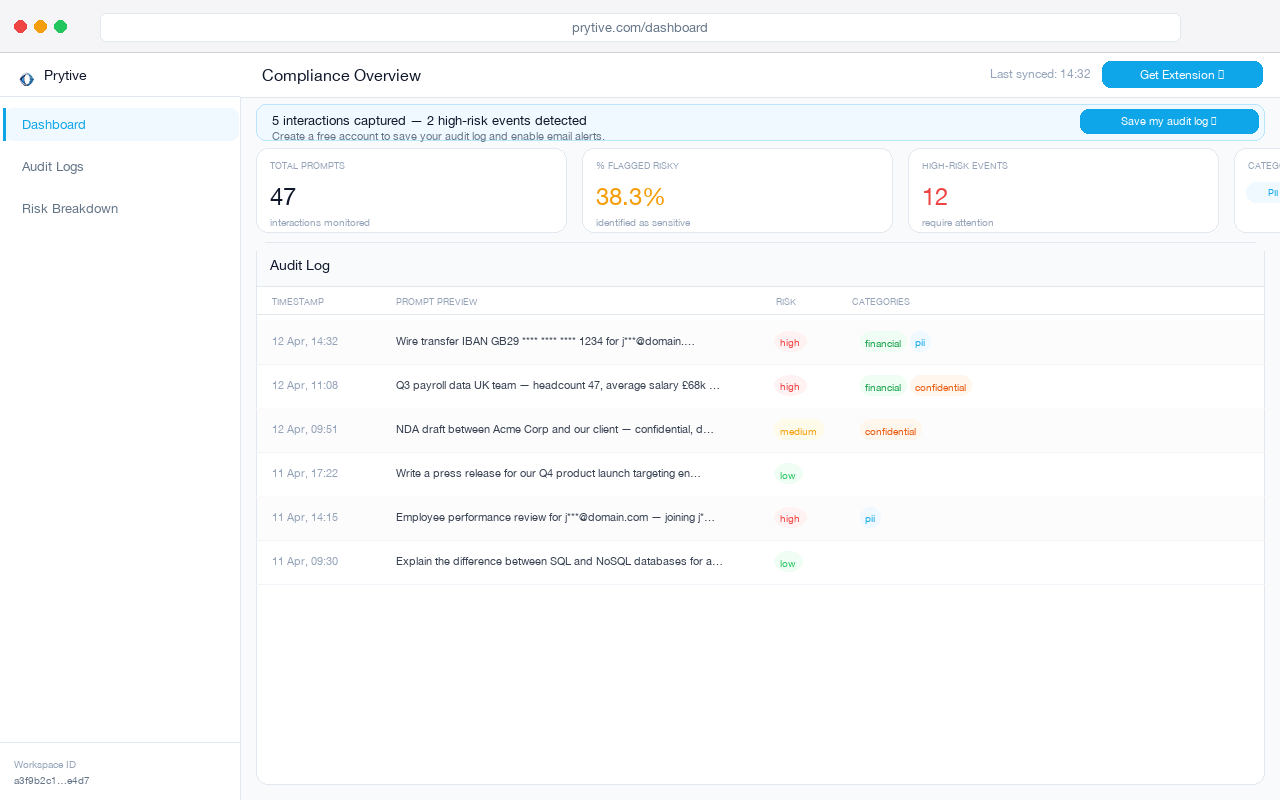
Show the redacted event trail. Show the category of data detected. Show the prompt was blocked or sanitised. Show what your team reviewed. If you cannot produce that under deadline, the rest of the conversation gets short.
{kind=link}
Why having a policy but no telemetry can make you look worse
GDPR Article 83(5) sets the top penalty tier: up to €20 million or 4% of total worldwide annual turnover, whichever is higher. Article 83(2) then tells regulators how to calibrate the penalty, including the controller's degree of responsibility, taking into account technical and organisational measures.
That last part should make every DPO and GC uneasy.
If you issued a policy acknowledging the risk, trained people on it, and then deployed no meaningful controls and kept no log, you have documented awareness without action. You knew enough to write the warning and not enough to instrument the risk.
That is not a charming middle ground. It is evidence.
There is a contrarian point here. A company with neither policy nor controls is negligent. A company with policy but no controls may look wilfully decorative. One is asleep at the wheel. The other installed a dashboard sticker and called it steering.
I would not count on that argument as a defence brief, but I would expect it to colour how regulators read responsibility under Article 83(2).
The prompt patterns most likely to create a record you cannot defend
Three prompt types show up again and again in internal reviews.
First, bulk exports used for convenience. CRM data, support queues, pricing sheets, claim notes. The employee is not trying to exfiltrate data. They are trying to finish work faster than your approved workflow allows.
Second, special category data under GDPR Article 9. Healthcare and employee-relations teams are especially exposed.
The patient feedback example above is not hypothetical law-school fodder. It is normal operational language. Which is exactly why generic awareness training fails. People do not experience their own work as “high-risk AI use.” They experience it as Tuesday.
Third, fake anonymisation workflows. “Anonymise this, then summarise it” sounds prudent right up until you notice the personal data was sent to the model first. If your controls do not catch that at paste time, your post-incident position is poor. For legal teams thinking about confidentiality and downstream waiver risk, law firm privilege waiver risks with ChatGPT is the adjacent problem in a different suit.
Three accountability artifacts every controller should be generating now
If Article 5(2) is the centre of gravity, your evidence base needs to exist before the incident.
First, an in-browser control record. You need proof that prompts containing PII, financial data, or confidential material were detected and either blocked or redacted before submission.
Second, a redacted audit log tied to user, date, tool, and risk category. Not raw sensitive content. That creates a second mess. You need enough detail to demonstrate control operation without stockpiling the very data you are trying to protect.
Third, a testing record for Article 32. Show that you assessed effectiveness over time: false positives, missed detections, policy changes, retraining, and exception handling. If you need a response framework once something slips through, the 72-hour AI incident response playbook is the clock you will be running against.
None of this is glamorous. Good compliance evidence rarely is. It is timestamps, categories, actions taken, and enough context to survive regulator scrutiny without forcing your team into archaeological digs across screenshots and Slack threads.
The next major fine will not arrive because someone in a basement popped a zero-day. It will arrive because an employee pasted live personal data into ChatGPT, your company knew this was possible, and your only artefact was a policy nobody could operationalise.
Generate the Article 5(2) evidence base before you need to produce it under deadline. A 7-day Prytive audit is enough to start.